

Ever since the introduction of Stream APIs, the Java community began to get accustomed to what we call functional programming (along w/ parallelization), but little do we know what the implications of using the stream() vs parallelStream() are.
- Do the Stream APIs abstract computational details at the cost of performance?
- Does parallelStream() make the processing of stream faster?
- If it does, does it mean we should always go for it?
- Does parallelizing matter if there's a single core?
Patience! All these will be answered! The text-book definition would say stream() would fetch us series of data in sequential fashion while parallelStream() would parallelize the data stream. Blah and blah! Fast forward to a more practical explanation...
1. Stream API: The problem and the solution.
Let's take a look at the below function that aims to compute the total sum of POSITIVE integers in a list:
int totalSumInList(List<Integer> list) {
Iterator<Integer> it = list.iterator();
int sum = 0;
while (it.hasNext()) {
int num = it.next();
if( num > 0 ) {
sum += num;
}
}
return sum;
}
There are three major problems with this approach:-
- Even though we only wanna know the sum of integers, we have to provide how the iteration will take place. This is also called external iteration because client program is handling the algorithm to iterate over the list.
- The program is sequential in nature, there is no way we can do this in parallel easily.
- There is a lot of code to perform a really simple task.
Java Stream API was introduced just for the purpose of overcoming the above issues. Developers routinely use abstractions to remove themselves from the lower level details and talk in higher order concepts. It’s why we collectively don’t write in assembler much these days. Streams are just another way of doing that: they abstract away “how” the code works and lets you focus on “what” it is doing.
To answer the above three issues :-
- Java Stream API makes use of Internal iteration strategies and provides several features such as sequential and parallel execution, filtering based on the given criteria, mapping, etc. with a scope of optimization.
- Just by invoking parallelStream(), the data pipeline is parallelized and seeks to improve performance for large collections.
- Lambdas and functional interfaces are heavily used and thus makes the code concise and readable.
Summing up, using the Stream API, the above function could be re-written as -
private static int totalSumInList(List<Integer> list) {
return list.stream().filter(num -> num > 0).mapToInt(i -> i).sum();
}
2. Stream API: The Side-effect of the solution.
Having said that life becomes easier with Stream API, it also introduces performance drag (obviously!). It is slow!
But how slow exactly?
Well it depends on who you ask and exactly what code they are using to test with. I’ve seen benchmarks that put it anywhere from 2–10x slower than naive code. The lack of consistency proves at least one thing: writing performant benchmarking code is difficult! Changing the implementation type of the backing data structure, or how long the code is warmed up, or even whether you account for auto boxing can drastically change the results and lead to incorrect conclusions.
Nevertheless, there is always almost an overhead cost. But this may be compensated by various factors such as parallelizing for larger collections, making use of "lazy" streams to improve performance, etc. So it all boils down to how well the stream construct is written.
3. stream() vs parallelStream()
Now that we know what the Stream API is all about, let's get to the heart of the case: what, when and why parallelize.
Using parallelStream(), the default sequential stream of data is partitioned by Java Runtime into multiple sub-streams. Aggregate operations iterate over and process these sub-streams in parallel and then combine the results. So, we can use Parallel Streams if we have performance implications with the Sequential Streams.
However, should we?
Let's take a look, using an example of my favourite character - Minions!
void sequentialStreamPerformance(Collection <Minion> minions) {
long t1 = System.currentTimeMillis(), count;
count = minions.stream()
.filter(x-> (x.getNumberOfEyes() == 1))
.filter(x-> x.getFavouriteFruit().equals("Banana"))
.filter(x-> x.getName().startsWith("B"))
.count();
long t2 = System.currentTimeMillis();
System.out.println("Count = " + count + " Normal Stream takes " + (t2-t1) + " ms");
}
void parallelStreamPerformance(Collection <Minion> minions) {
long t1 = System.currentTimeMillis(), count;
count = minions.parallelStream()
.filter(x-> (x.getNumberOfEyes() == 1))
.filter(x-> x.getFavouriteFruit().equals("Banana"))
.filter(x-> x.getName().startsWith("B"))
.count();
long t2 = System.currentTimeMillis();
System.out.println("Count = " + count + " Parallel Stream takes " + (t2-t1) + " ms");
}
Running the above two with incremental collection size of minions and noting the time taken, here's a chart that represents the data.
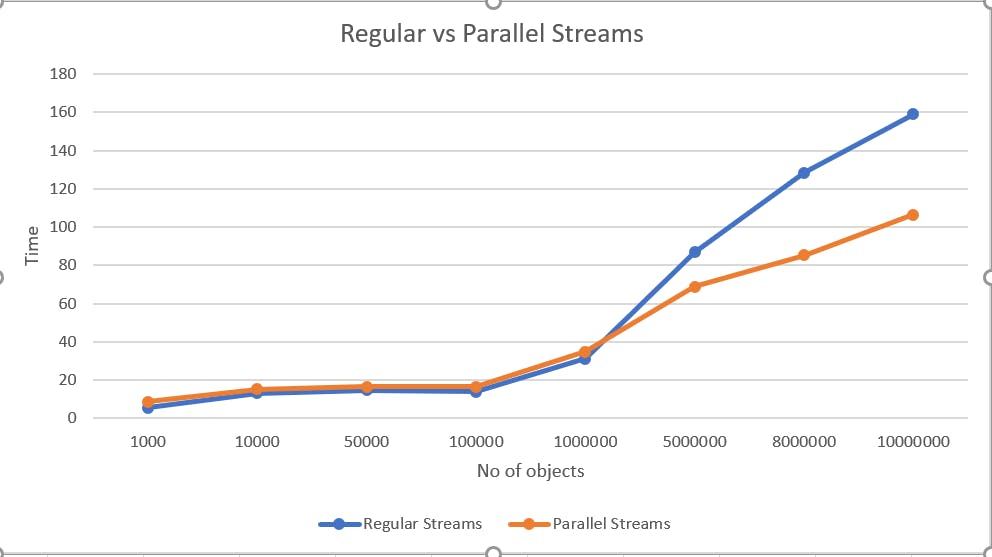
Observations
- Sequential streams outperformed parallel streams when the number of elements in the collection was less than 1,000,000.
- Parallel streams performed significantly better than sequential streams when the number of elements was more than 1,000,000.
Problem #1
Solving a problem in parallel always involves performing more actual work than doing it sequentially. Overhead is involved in splitting the work among several threads and joining or merging the results.
Problem #2
What if Minion::getFavouriteFruit is CPU intensive operation (for some weird reason) ? Well, that's fine if there are multiple CPU cores but if there's a single core, then we're back to square one. But well, as it turns out, machines usually have multiple available cores these days!
Problem #3
What if Minion::getFavouriteFruit is Network I/O intensive operation (for some weirder reason) ? Here, we do not deal with a CPU-intensive operation, but we can take advantage of parallelization too. It's a good idea to execute multiple network request in parallel. Again, a nice task for parallel streams, right?
Nope.
The problem is that all parallel streams use common fork-join thread pool, and if you submit a long-running task, you effectively block all threads in the pool. Consequently, you block all other tasks that are using parallel streams. Imagine a servlet environment, when one request calls getFavouriteFruit() and another one calls some other stream API, one will block the other one even though each of them requires different resources. What's worse, you can not specify thread pool for parallel streams; the whole class loader has to use the same one.
4. Long Story Short.
- Use of Stream APIs trade speed for readability/maintainability. If you are working on a compiler or library code this might not be a great tradeoff, but for the majority of corporate developers this is fantastic. Better to quickly understand and fix than to break your head on a customer-raised bug at 2am!
- A parallel stream has a much higher overhead compared to a sequential stream. Coordinating the threads takes a significant amount of time. Sequential streams sound like the default choice unless there is a performance problem to be addressed.
- The default sequential stream performs better for a decently normal collection size while parallel streams performs better for larger size, provided the operations involved are not network I/O intensive.
And scene! Case closed!
Thanks for reading!